In July 2014, Dan Katz, Mike Bommarito, and I posted an early draft of our paper, “A General Approach for Predicting the Behavior of the Supreme Court of the United States (1816-2015).” After two years, and a lot of refinement, we have posted a revised version that is lightyears ahead. Our goal in this paper is to develop a single model that can predict cases at any point across two centuries of the Supreme Court’s history, from 1816-2015. New Justices come and go, doctrines change, and politics evolves–our model keeps humming along. Here is the abstract:
Building on developments in machine learning and prior work in the science of judicial prediction, we construct a model designed to predict the behavior of the Supreme Court of the United States in a generalized, out-of-sample context. Our model leverages the random forest method together with unique feature engineering to predict nearly two centuries of historical decisions (1816-2015). Using only data available prior to decision, our model outperforms null (baseline) models at both the justice and case level under both parametric and non-parametric tests. Over nearly two centuries, we achieve 70.2% accuracy at the case outcome level and 71.9% at the justice vote level. More recently, over the past century, we outperform an in-sample optimized null model by nearly 5 %. Our performance is consistent with, and improves on the general level of prediction demonstrated by prior work; however, our model is distinctive because it can be applied out-of-sample to the entire past and future of the Court, not a single term. Our results represent an advance for the science of quantitative legal prediction and portend a range of other potential applications.
Figure 5 displays out “heatmap,” which indicates how we did predicting each Justice over the past century during a given term. The darker green squares indicate we beat the baseline model. The darker pink squares indicate we lost to the baseline model.
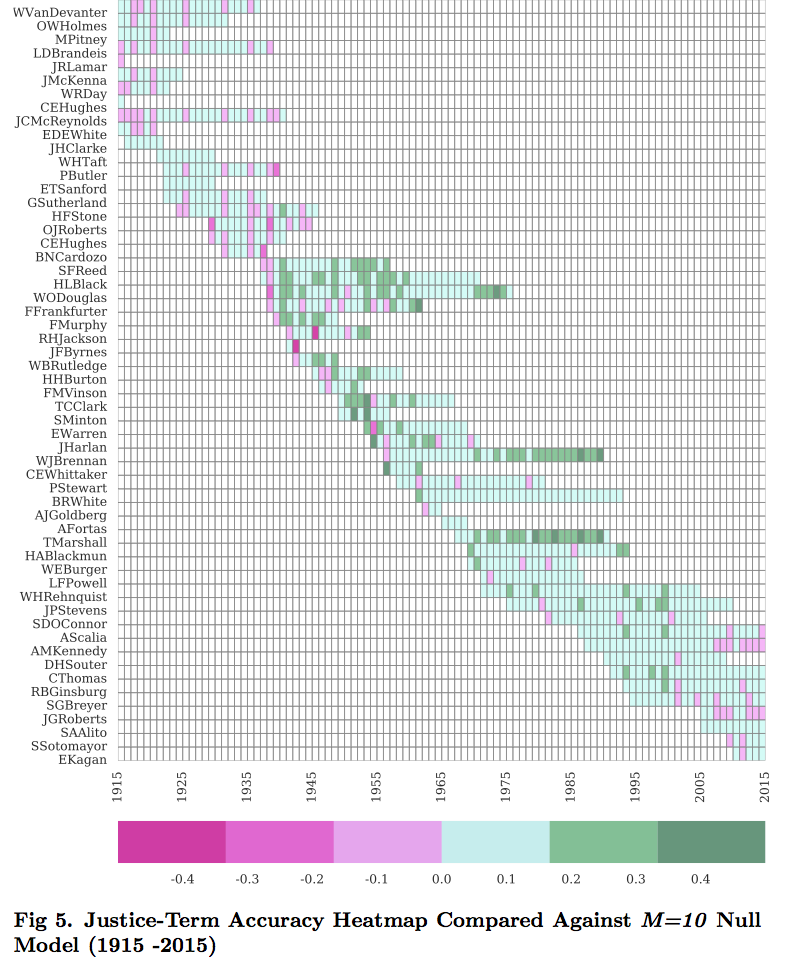
Figure 1 plots our case and justice accuracy over the past two centuries.
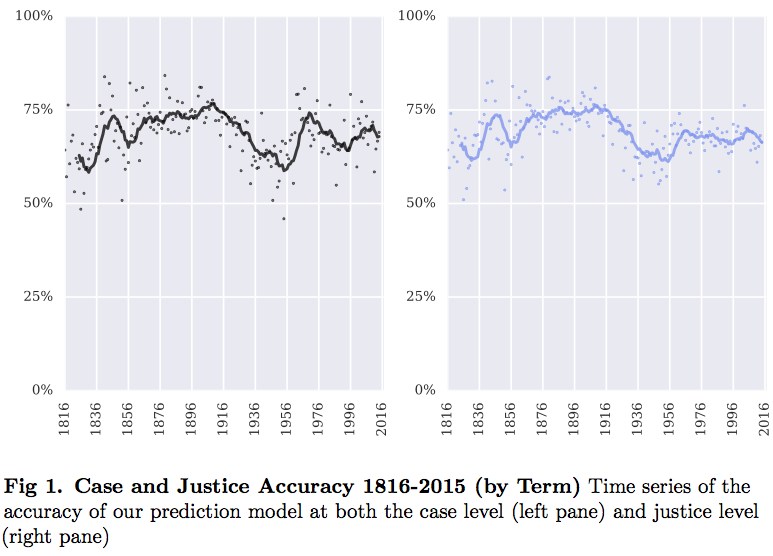
Over the past decade, roughly coinciding with the start of the Roberts Court, our accuracy has been declining. My colleague Dan likes to compare such swings to a “Bear Market” for financial models. Over the long-haul–and this is the purpose of our “general” model–we are still beating a “null model,” such as predicting all reversals.
But, this decline does raise an important point that we will address in a separate law-review style article.
After more than a century of soundly defeating all three null models, the performance of our prediction model has dipped during the Roberts Court (as compared against the always guess reverse heuristic and M=10 null model). Within the scope of this study, it is difficult to determine whether this represents some sort of systematic change in the Court’s macro-dynamics. However, thus far, it does appear that the Roberts Court is less predictable than its immediate predecessors.
This is a very exciting project, and I hope to have news about its placement shortly.